
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron (previously Deep Science), aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
This week in AI, a new study reveals how bias, a common problem in AI systems, can start with the instructions given to the people recruited to annotate data from which AI systems learn to make predictions. The coauthors find that annotators pick up on patterns in the instructions, which condition them to contribute annotations that then become over-represented in the data, biasing the AI system toward these annotations.
Many AI systems today “learn” to make sense of images, videos, text, and audio from examples that have been labeled by annotators. The labels enable the systems to extrapolate the relationships between the examples (e.g., the link between the caption “kitchen sink” and a photo of a kitchen sink) to data the systems haven’t seen before (e.g., photos of kitchen sinks that weren’t included in the data used to “teach” the model).
This works remarkably well. But annotation is an imperfect approach — annotators bring biases to the table that can bleed into the trained system. For example, studies have shown that the average annotator is more likely to label phrases in African-American Vernacular English (AAVE), the informal grammar used by some Black Americans, as toxic, leading AI toxicity detectors trained on the labels to see AAVE as disproportionately toxic.
As it turns out, annotators’ predispositions might not be solely to blame for the presence of bias in training labels. In a preprint study out of Arizona State University and the Allen Institute for AI, researchers investigated whether a source of bias might lie in the instructions written by data set creators to serve as guides for annotators. Such instructions typically include a short description of the task (e.g. “Label all birds in these photos”) along with several examples.

Image Credits: Parmar et al.
The researchers looked at 14 different “benchmark” data sets used to measure the performance of natural language processing systems, or AI systems that can classify, summarize, translate, and otherwise analyze or manipulate text. In studying the task instructions provided to annotators that worked on the data sets, they found evidence that the instructions influenced the annotators to follow specific patterns, which then propagated to the data sets. For example, over half of the annotations in Quoref, a data set designed to test the ability of AI systems to understand when two or more expressions refer to the same person (or thing), start with the phrase “What is the name,” a phrase present in a third of the instructions for the data set.
The phenomenon, which the researchers call “instruction bias,” is particularly troubling because it suggests that systems trained on biased instruction/annotation data might not perform as well as initially thought. Indeed, the coauthors found that instruction bias overestimates the performance of systems and that these systems often fail to generalize beyond instruction patterns.
The silver lining is that large systems, like OpenAI’s GPT-3, were found to be generally less sensitive to instruction bias. But the research serves as a reminder that AI systems, like people, are susceptible to developing biases from sources that aren’t always obvious. The intractable challenge is discovering these sources and mitigating the downstream impact.
In a less sobering paper, scientists hailing from Switzerland concluded that facial recognition systems aren’t easily fooled by realistic AI-edited faces. “Morphing attacks,” as they’re called, involve the use of AI to modify the photo on an ID, passport, or other form of identity document for the purposes of bypassing security systems. The coauthors created “morphs” using AI (Nvidia’s StyleGAN 2) and tested them against four state-of-the art facial recognition systems. The morphs didn’t post a significant threat, they claimed, despite their true-to-life appearance.
Elsewhere in the computer vision domain, researchers at Meta developed an AI “assistant” that can remember the characteristics of a room, including the location and context of objects, to answer questions. Detailed in a preprint paper, the work is likely a part of Meta’s Project Nazare initiative to develop augmented reality glasses that leverage AI to analyze their surroundings.
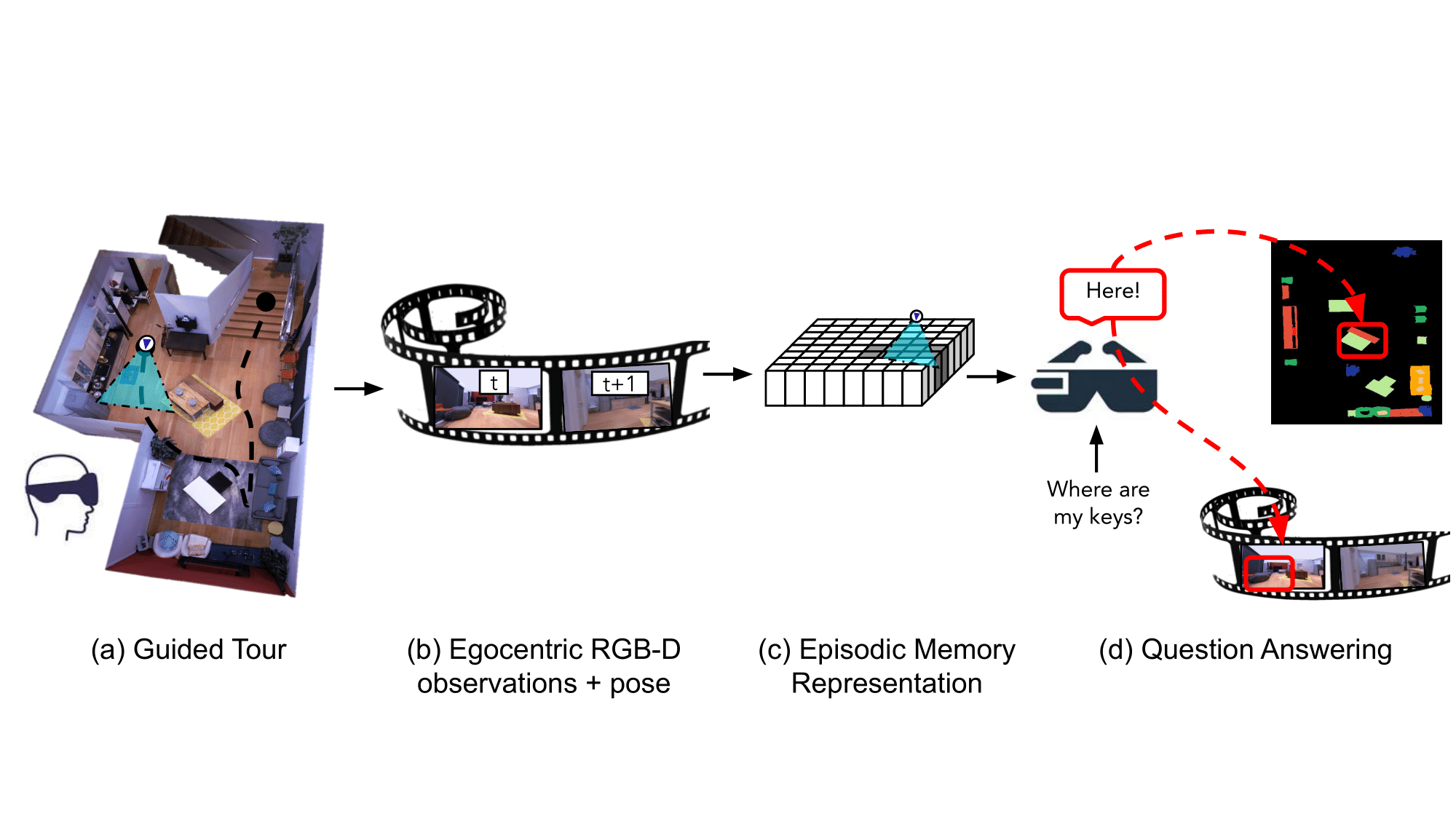
Image Credits: Meta
The researchers’ system, which is designed to be used on any body-worn device equipped with a camera, analyzes footage to construct “semantically rich and efficient scene memories” that “encode spatio-temporal information about objects.” The system remembers where objects are and when the appeared in the video footage, and moreover grounds answers to questions a user might ask about the objects into its memory. For example, when asked “Where did you last see my keys?,” the system can indicate that the keys were on a side table in the living room that morning.
Meta, which reportedly plans to release fully-featured AR glasses in 2024, telegraphed its plans for “egocentric” AI last October with the launch of Ego4D, a long-term “egocentric perception” AI research project. The company said at the time that the goal was to teach AI systems to — among other tasks — understand social cues, how an AR device wearer’s actions might affect their surroundings, and how hands interact with objects.
From language and augmented reality to physical phenomena: an AI model has been useful in an MIT study of waves — how they break and when. While it seems a little arcane, the truth is wave models are needed both for building structures in and near the water, and for modeling how the ocean interacts with the atmosphere in climate models.

Image Credits: MIT
Normally waves are roughly simulated by a set of equations, but the researchers trained a machine learning model on hundreds of wave instances in a 40-foot tank of water filled with sensors. By observing the waves and making predictions based on empirical evidence, then comparing that to the theoretical models, the AI aided in showing where the models fell short.
A startup is being born out of research at EPFL, where Thibault Asselborn’s PhD thesis on handwriting analysis has turned into a full-blown educational app. Using algorithms he designed, the app (called School Rebound) can identify habits and corrective measures with just 30 seconds of a kid writing on an iPad with a stylus. These are presented to the kid in the form of games that help them write more clearly by reinforcing good habits.
“Our scientific model and rigor are important, and are what set us apart from other existing applications,” said Asselborn in a news release. “We’ve gotten letters from teachers who’ve seen their students improve leaps and bounds. Some students even come before class to practice.”

Image Credits: Duke University
Another new finding in elementary schools has to do with identifying hearing problems during routine screenings. These screenings, which some readers may remember, often use a device called a tympanometer, which must be operated by trained audiologists. If one is not available, say in an isolated school district, kids with hearing problems may never get the help they need in time.
Samantha Robler and Susan Emmett at Duke decided to build a tympanometer that essentially operates itself, sending data to a smartphone app where it is interpreted by an AI model. Anything worrying will be flagged and the child can receive further screening. It’s not a replacement for an expert, but it’s a lot better than nothing and may help identify hearing problems much earlier in places without the proper resources.
from TechCrunch https://ift.tt/pLR8XHf
0 comments:
Post a Comment